



Enterprise IT disaster recovery (ITDR) planning and architecture is changing dramatically with proliferating threat and failure scenarios, an ever-increasing number of attack surfaces and the increased impact (or blast radius) of security or resilience-related incidents. Businesses must now consider multiple sites on-prem and/ or cloud running thousands of devices (servers, storage and networking components), supporting hundreds of different business applications and services, many of which are highly interdependent.
An increasing number of resilience scenarios, such as infrastructure failures, security breaches or human errors, can affect the confidentiality, integrity and/or availability of a subset of services at a site. In these scenarios, rapidly isolating and relocating only the affected applications or application components to another environment would be more desirable than attempting to relocate all applications at the site to an alternative, trusted recovery environment.
How can enterprises transition legacy applications from traditional DR strategies to more modern, granular and (increasingly) cloud-based recovery strategies?
Legacy recovery challenges
Many organizations have, for various reasons, ended up with an all-or-nothing recovery strategy. Because isolating and failing over an individual service or service group was not typically factored into the design of legacy systems at an infrastructure level, transitioning to a modern granular recovery strategy can be a challenge.
To help create a remediation transition plan, every application needs a recovery strategy that serves as a north-star to guide infrastructure teams as they modernize legacy environments, and application teams as they improve their application resilience posture.
What is a modern resilience strategy?
Creating a cohesive resilience strategy for an application involves understanding several elements that are important and should be considered foundational:
- Understanding the application business affinity
- Defining application recovery objectives
- Identifying application network co-dependencies
- Assigning the application to a (new or existing) recovery group
A recovery solution, involving specific configurations of application and/or infrastructure services, can then be designed to implement the recovery strategy for all applications in the same recovery group, enabling a managed transition to modernized recovery strategies.
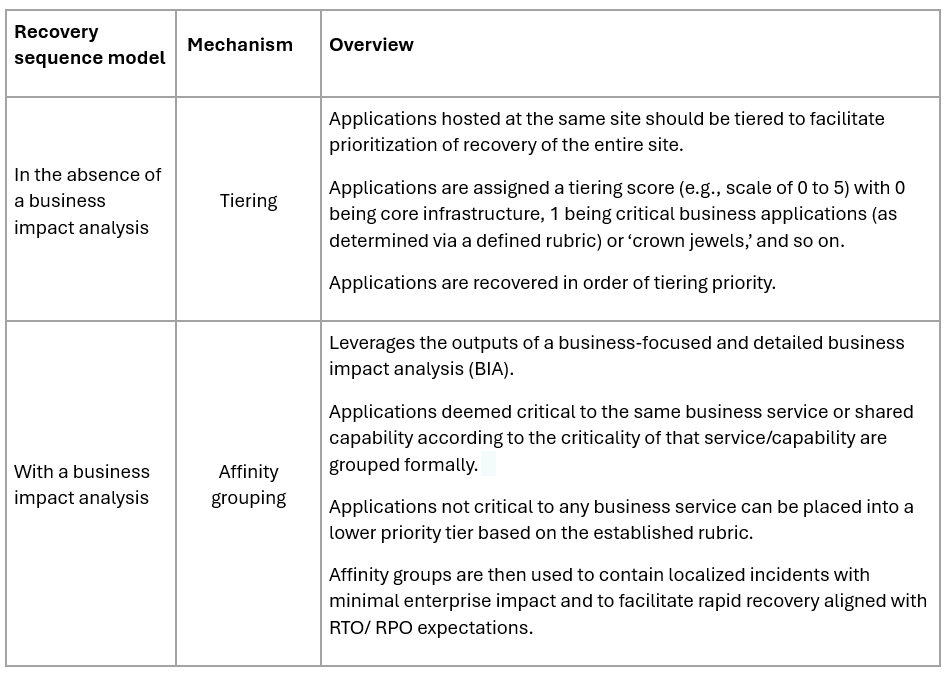
Understanding the application business affinity
The application business affinity is a view of how the application supports business processes, and whether those processes are critical to the overall business. Affinity can be approximated using tiering (as described below), or via an affinity group derived from a detailed business impact analysis (DRII) and/or current-state business architecture documentation.
Application recovery requirements are best expressed in terms of recovery time objective (RTO) and recovery point objective (RPO). The RTO indicates the maximum time the business can tolerate the application being unavailable. The RPO represents the data loss tolerance, and is represented as an amount of time, prior to the point of disruption, e.g., an RPO of 15 minutes indicates no more than 15 minutes of data will ever be unavailable.
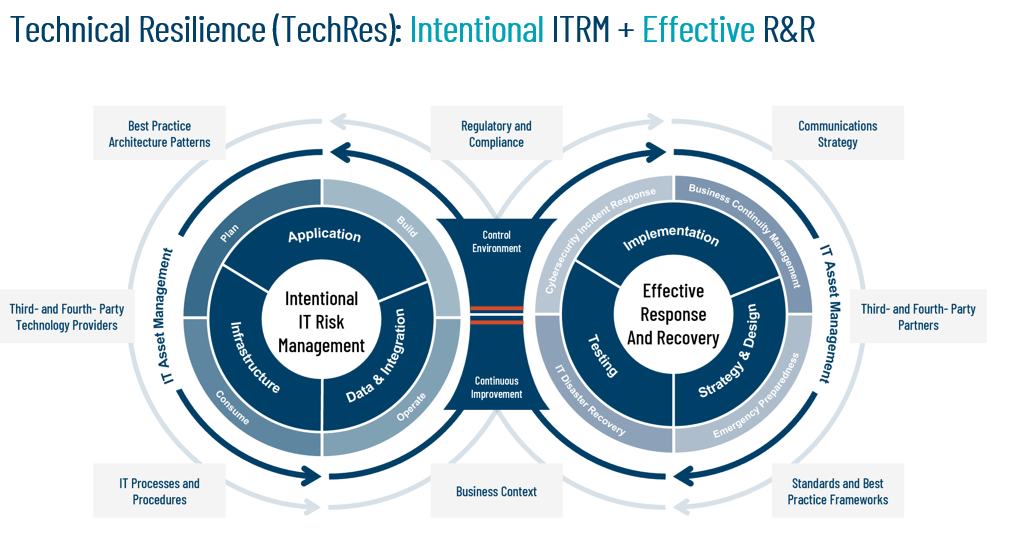
The capability of technology teams to design, implement, and maintain strategies to ensure the RTOs and RPOs are achievable is based on the early inclusion of operational risk considerations in solution design activities, as indicated in the graphic below:
Identifying application network co-dependencies
To co-manage applications from an infrastructure resilience perspective, network dependencies must be known and consistently managed. This is especially critical for zero-trust network infrastructure. Knowing these dependencies will also ensure failed-over applications can access dependent services, and, further, dependent services can find failed-over applications.
Ideally, application dependencies will be documented by enterprise architecture teams, but many legacy applications have integrations that have evolved over time across multiple projects and are often not well documented. In these circumstances, discovery tools (e.g., Azure Migrate/ Dr. Migrate or AWS Migration tools) can be used to capture and map application dependencies based on network traffic.
To effectively use this data for managing dependencies, configuration management databases (CMDBs) may need to be validated and, when needed, gaps addressed, which may require surveying or soliciting information from application owners.
Applications with integrations which span affinity groups may need significant remediation – and alignment to adequate CMDB coverage – to ensure integration solutions can accommodate the relocation of services.
Assigning applications to recovery groups
Next, application recovery groups can be defined (i.e., when all the above inputs are considered). Applications should be assigned to, at most, one recovery group.
A recovery group has the following attributes:
- Linkage to the enabled business service(s)
- A set of applications and related configuration items
- A catalog of dataflows, including protocols and internal and external endpoints
- Group recovery objectives
Defining a transition strategy
Having defined the necessary recovery groups, application and infrastructure teams can implement remediation and investment efforts to enable the transition of applications to their target recovery groups.
Effective recovery group strategies, leveraging cloud-enabled capabilities for cost effectiveness, allow failed-over applications to remain running indefinitely in their recovery environment, and can greatly simplify the fail-back process. With the advent of cloud-delivered services, the distinction between production and DR environments can become a matter of a code configuration change, ultimately enabling a highly resilient, adaptive technology operating environment that seamlessly bridges resilient system design with effective response and recovery.
Granular DR improvements can often be accomplished in alignment with enterprise zero-trust initiatives and/or cloud migration efforts, which are often initiatives already funded or underway in organizations.
To learn more about our technology resilience solutions, contact us or download our Guide to Business Continuity and Resilience and refer to Achieving Resilience Starts at the Top.



