
Data is everywhere! As the most important factor in the business analysis world, data can be gathered from a variety of sources within an organization, including registrations, sales, IoT devices, and many others. It’s not uncommon to find the same customer under the same name and date of birth duplicated in our clients’ systems via different applications. With business growing rapidly and increasing use of new technologies, we find our clients struggling to maintain the uniqueness and quality of their data, making it impossible to paint the whole picture of the customer’s journey, subsequently losing valuable business insight and unable to facilitate decision-making.
While most ETL tools are traditionally used for data warehousing and integration projects, with the additional features of SAP Data Quality Management (DQM), we can achieve data globalization and derive best records. We have found using DQM effective in solving client-facing data issues. In this post, we share our best practices on how to alleviate a customer’s stress over data quality and uniqueness and how to effectively handle multiple member accounts.
Data cleansing, validation and standardization
Performing data cleansing, validation and standardization is extremely helpful prior to performing matching and consolidation on the data. This step should increase the matching store and allow better consolidation on any given data set. For North American data, we normally use the EnglishNorthAmerica_DataCleanse transform to parse, cleanse and standardize personal data, which includes email, phone number, first and last names and date of birth if available from the source.
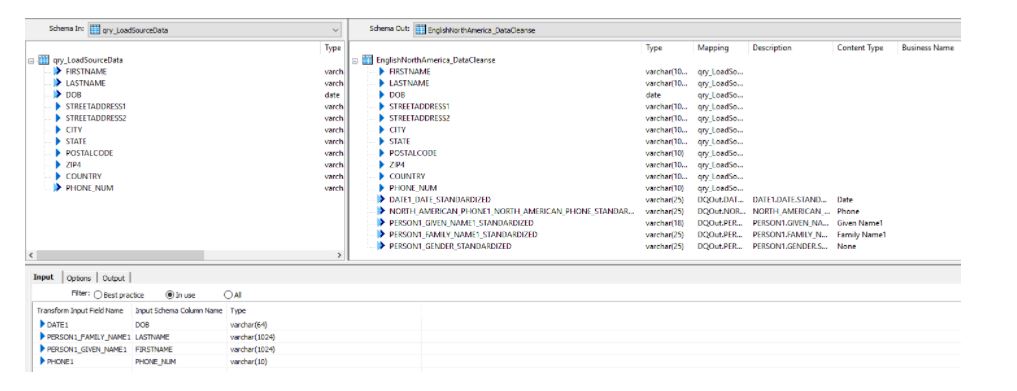
Within the options section, it is our general practice to ensure the standardization options are consistently applied for all data cleanse transforms. Such options should include capitalization, remove punctuation, date formats, and phone delimiter settings.
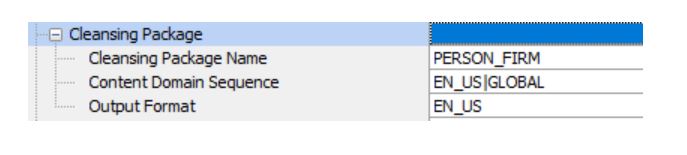
Building a personalized cleansing package by analyzing a client’s source data is also a suggested approach at beginning of the project. This can also be utilized by a client site’s business resources to continuously enforce correct translation of data even after project go-live.
Address cleansing is the next thing to check. When attempting to dedupe a person, addresses are a point of contention if data must be reduplicated. As an example, think about all the abbreviations for the types of streets (Court, Ct., Ct,), add misspellings, upper/lower case, wrong zip codes, incomplete information and all the other permutations of addresses, and the address table might look like this, all for the same family:

What if we define a standard and make all our addresses the same, utilizing these criteria:
- First letter upper case
- Apartments/Units on a new line
- ISO3166-2 State (US-GA)
- 5+4 digit zip code (30318)
Our globalized address output now looks like this:

It is possible to write a standardization formula from scratch; however, that would be complicated and would require including all the different types of street address suffixes, which could result in nebulous mapping that isn’t easily maintainable. However, using SAP DQM makes this easy. With a few clicks and some options, users can choose either the USA regulatory address cleanse (URAC) or the global address cleanse (GAC) and have a standard address output. Both can be found under transforms in the SAP data services application.
Data matching and consolidation
Once data has been cleansed, validated and standardized, we can then utilize the matching and consolidation function of DQM to minimize the number of duplicates from heterogenous or homogenous source data. Match transforms are located under data quality transforms in the local object library.
There are built-in match transforms that can be used directly, but we recommend building based on source data. We have found this method to be most efficient and allows us to tune the matching score to better suit our client’s requirements. Match transforms involve complex calculation rules and logics on how to archive best results. The first step should be setting up a reasonable break key in such a way that the groups would not be too large or too small to ensure a good execution performance. Break keys can be pre-defined before the match transform, or it can be defined under the break group section in the match editor.
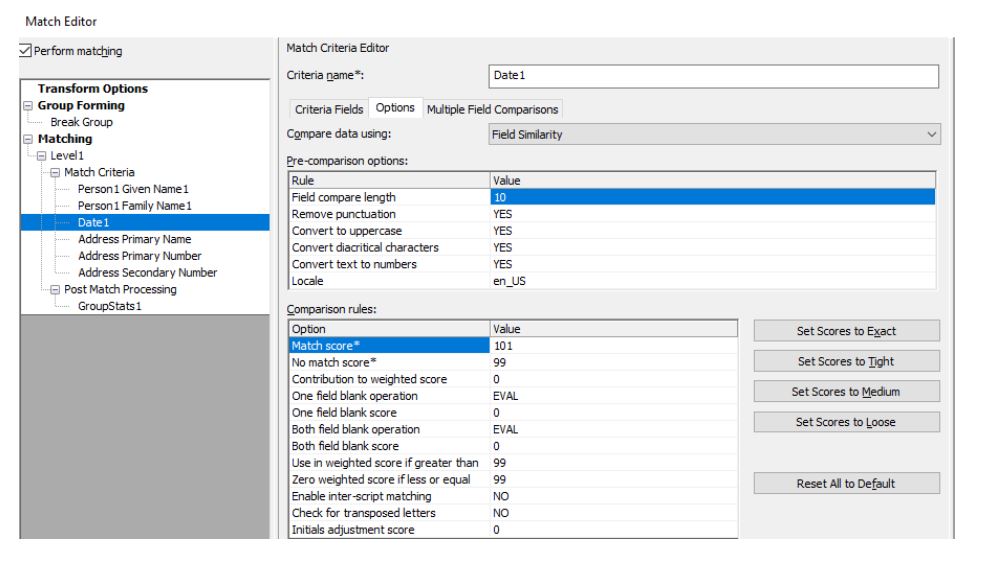
Matching criteria fields have a few important options to tune, including field compare length, no match score and field blank operations. Match score and weighted score options should be used depending on which matching strategy is chosen, weighted scoring or multiple fields criteria comparison. A value 101 on the match score field ensures multiple records should be compared and evaluated to derive the final match or no match score. Contribution to weighted score should be non-zero when the weighted scoring method is used.
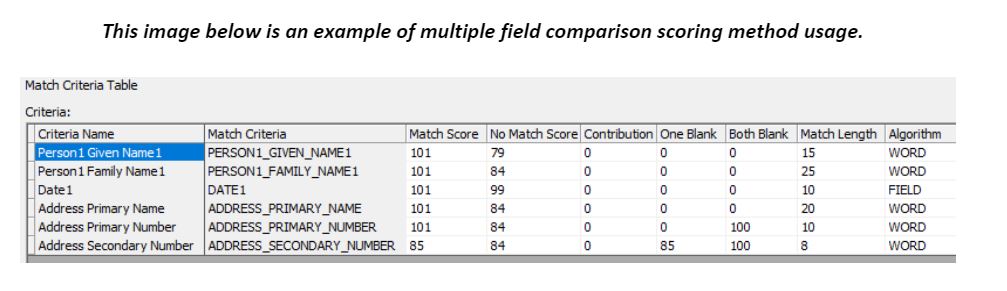
One of the key outputs of the match transform is the group number, which indicates if there is a match or not. With our best practice, multiple match strategies are applied on the same set of data to archive the best result. This set of group numbers is then fed into the associate transform to perform the final consolidation step.
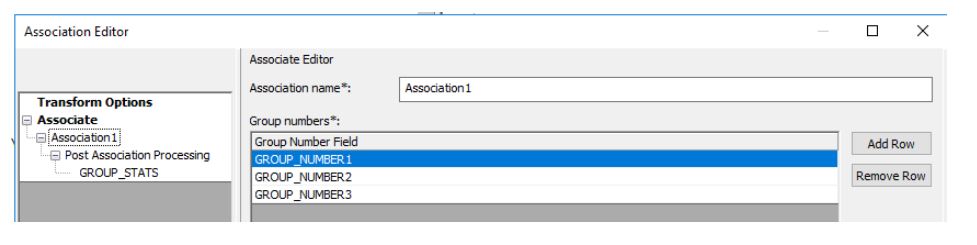
Association output is a single group number that associates all match results together. For example, if two of the three records are associated by match strategy one, and one of the two is associated with record three by match strategy two, as a result, all three records would be associated and would be assigned a same final association group number.
Putting it all together
Putting everything together, we’ll start with a family of three that have multiple customer instances and addresses in completely different formats. Using the associate match with the cleansed addresses and the name, we determined that these members are in the same family. To recap, here’s the starter data set from a source system. For simplicity, we’ll ignore data warehousing concepts like surrogate keys, but using address cleansing, we’ll de-duplicate the addresses, use the name cleanse and the matching transform, we’ll match customers who are the same, but exist as different IDs, and match this family to each other.
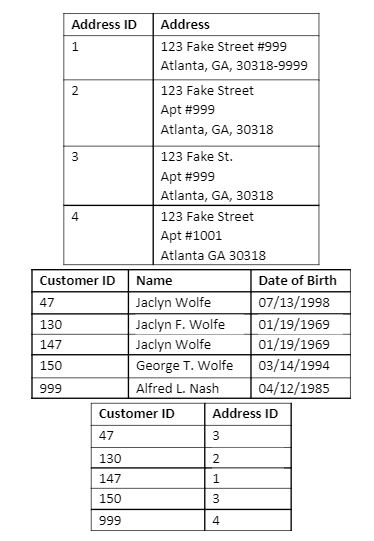
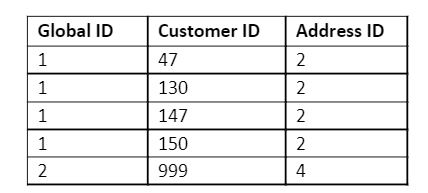
In the example above, the Wolfe family all live together, with Jaclyn Wolfe, Sr. having two different customers. However, Alfred Nash is a neighbor of the Wolfe family and shouldn’t be grouped with them. This is shown in the data below, where each member of the Wolfe family has a global ID = 1, and Alfred Nash has a global ID = 2, with the address ID linking to the best address available.
Protiviti understands that an organization’s data is essential to its success, yet as companies generate more and more data every day, the ability to access, manage and transform that data into valuable business intelligence becomes more difficult. Our data management team helps organizations through the entire information lifecycle, including strategy, management and reporting, to ensure decision-makers have the right information at the right time. Our data management project experience includes:
- Identifying data issues
- Designing data warehouses and data strategy
- Defining data mapping logic
- Implementations
- Testing and support UAT
- Deployment
To learn more about our SAP capabilities, contact us or visit Protiviti’s SAP consulting services.



